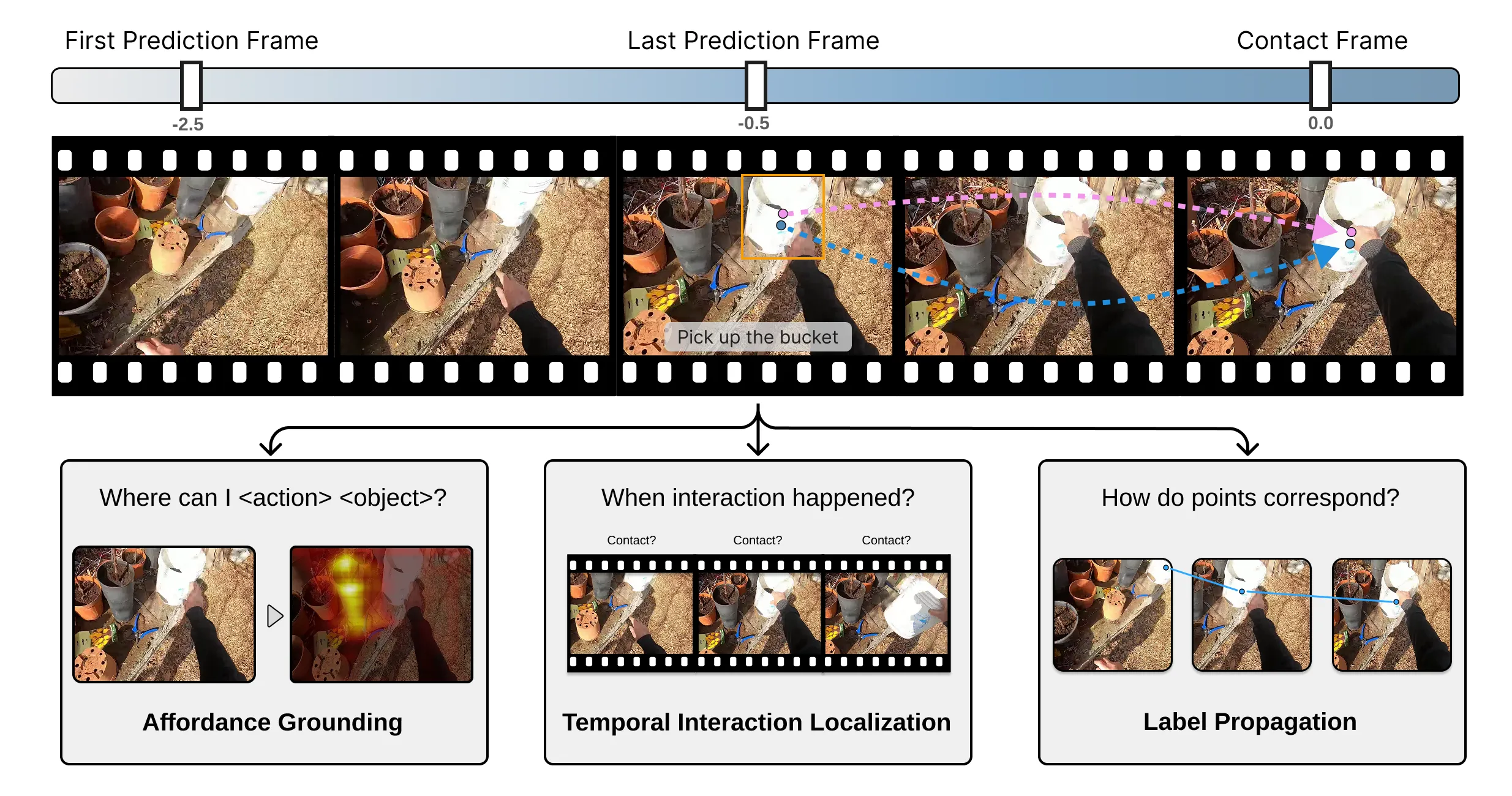
Task 1: Affordance Grounding. Predicting the spatial contact heatmaps for future interactions given an observation window. Evaluated with varying spatial thresholds to demonstrate the severity of the physicality gap at pixel-precision.
HiFiEgo overview: We annotate temporal windows, contact frames, fingertip contact points, boxes, and semantic actions for grounding, interaction localization, and label propagation.
Abstract
Embodied AI demands more than recognizing objects: it requires knowing precisely where to make contact, down to the fingertip, to enable dexterous manipulation. Despite growing interest in affordance grounding, the field lacks evaluation infrastructure capable of measuring this physical precision, with existing benchmarks relying on coarse heatmaps that conflate object-level localization with contact-level accuracy. We introduce HiFiEgo, a large-scale egocentric benchmark with over 20K manually annotated interaction events, each with temporally anchored contact frames, pixel-precise contact point labels, bounding boxes, and semantic action labels, sourced from unconstrained real-world egocentric videos. Using HiFiEgo, we expose a systematic physicality gap: state-of-the-art affordance methods that achieve up to 38% accuracy under coarse spatial thresholds collapse to roughly 1% at contact-level precision. We further provide the first standardized evaluation of egocentric data mining pipelines across three tasks, affordance grounding, contact frame localization, and backward label propagation, and show that compounding errors across pipeline stages prevent the pixel-level precision needed for reliable automatic supervision.
HiFiEgo Dataset
Real-World
Unconstrained Egocentric
Video Sequences
20K+
Manually Annotated
Interaction Events
Pixel-Precise
Temporal Contact Frames &
Fingertip Points
Interactive Dataset Map
Explore the diverse distribution of interactions in HiFiEgo. This data-driven t-SNE visualization is
fully interactive.
Pan, zoom, and click the larger bubbles to watch the exact 2.5-second
interaction clip!
Long-Tail Dataset Distributions
Detailed log-scale distribution of all annotated action classes, spanning 85 distinct verbs reflecting real-world egocentric interactions.
Log-scale distribution of unconstrained target object categories, demonstrating extensive long-tail presence critical for robust manipulation grounding.
High-Fidelity Annotation UI
Custom UI demonstrating the workflow for achieving pixel-precise temporal boundaries and spatial contact points.
Benchmarks & Leaderboard
| Method | PCK@1% ↑ | PCK@5% ↑ | PCK@10% ↑ | mDST ↓ | NSS ↑ |
|---|---|---|---|---|---|
| Image-based | |||||
| 3DOI ICCV 2023 | 1.36 | 18.37 | 38.72 | 0.17 | 0.93 |
| GLOVER++ CoRL 2025 | 0.87 | 14.48 | 35.17 | 0.16 | 0.62 |
| Video-based | |||||
| Joint Hand Motion CVPR 2022 | 0.41 | 7.98 | 26.42 | 0.17 | 1.11 |
| Retrieval-based | |||||
| Robo-ABC ECCV 2024 | 1.26 | 17.90 | 37.32 | 0.18 | 0.82 |
| RAM CoRL 2024 | 1.05 | 16.16 | 35.66 | 0.18 | 0.69 |
Last updated on ...